使用手册
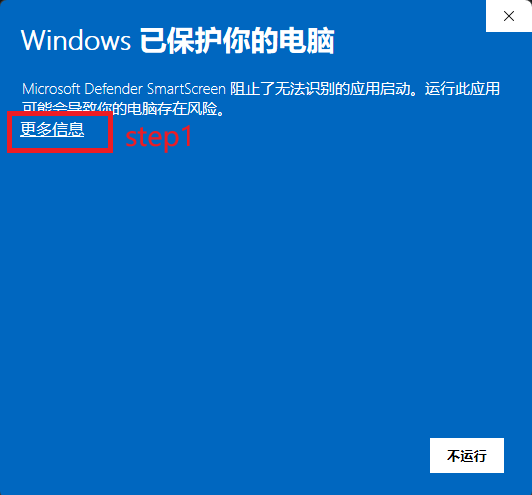
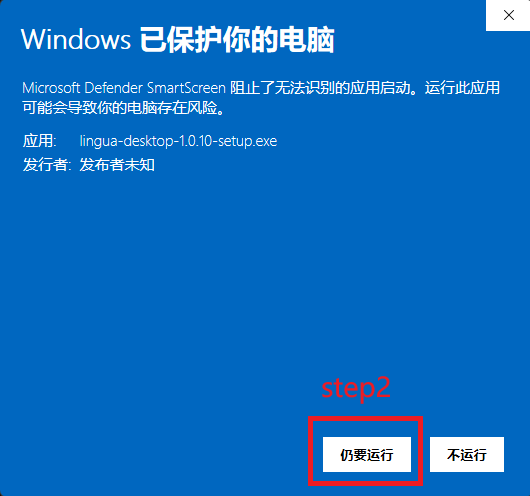
安装时被Microsoft Defender SmartScreen阻止?
我们作为初创团队目前没有能力购买昂贵的商业代码签名证书(交不起微软保护费),所以安装时可能会被windows阻止,如果你在安装时遇到这种情况,
请点击更多信息->仍要运行即可正常安装。
只有安装时才有可能会被阻止,后续运行时不会出现。
实时识别和离线识别模型区别
- 实时(流式)识别模型用于实时转录场景,非必选,配置了实时识别模型可以有低延迟的"边听边识别"的流式输出效果,当检测到一段话结束会进入离线识别阶段。
- 离线识别时拥有更完整的句子上下文,所以准确度更高,它会修正刚才实时模型产生的错别字,并补全标点符号。
离线识别模型选择
sense-voice或paraformer模型,中文准率高且识别速度快,
whisper系列模型支持的语言多,但由于架构不同,即使是small小规格模型,在个人电脑上的识别速度仍比较慢,
如果前面两个模型无法满足要求,可尝试使用whisper系列模型。
模型下载
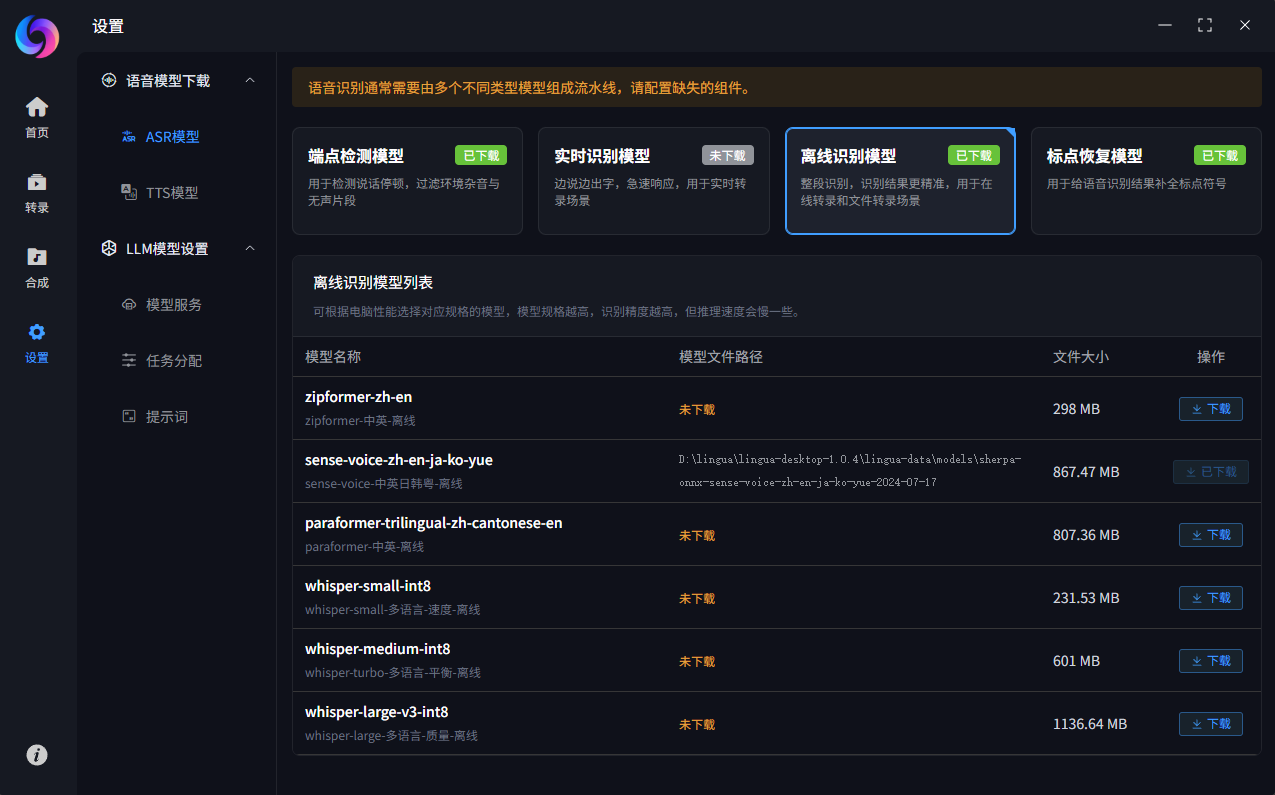
首次运行需进入 设置 > 模型下载页面中下载语音模型,ASR为语音识别模型,TTS为语音合成模型,按需下载即可。
其中端点检测模型、离线识别模型、标点恢复模型为必选项,
缺少任意一个都会导致转录功能无法使用。
实时识别和离线识别模型区别
- 实时(流式)识别模型用于实时转录场景,非必选,配置了实时识别模型可以有低延迟的"边听边识别"的流式输出效果,当检测到一段话结束会进入离线识别阶段。
- 离线识别时拥有更完整的句子上下文,所以准确度更高,它会修正刚才实时模型产生的错别字,并补全标点符号。
离线识别模型选择
sense-voice或paraformer模型,中文准率高且识别速度快,
whisper系列模型支持的语言多,但由于架构不同,即使是small小规格模型,在个人电脑上的识别速度仍比较慢,
如果前面两个模型无法满足要求,可尝试使用whisper系列模型。
模型服务商设置
- 根据你的需求选择模型服务商,Ollama通常不需要填写Api Key(你可以随便填写一个,不填写的话表单无法保存)
- 如果是云端模型,你需要先去对应服务商去注册账号,注册完后将Api Key填上
- 填写完Api Key后可以测试一下连通性,百炼平台和硅基流动平台中预设了一些常用模型,如果不满足需求则自行添加其它模型
- 添加模型时需要确认模型类型是否正确,如果类型不匹配可能导致功能无法正常使用,比如:总不能拿一个文本对话模型让它去做视觉识别,对吧
- 模型服务商可以只配置一个,也可以配置多个,支持不同服务商的模型混用,按需选择token性价比高的即可
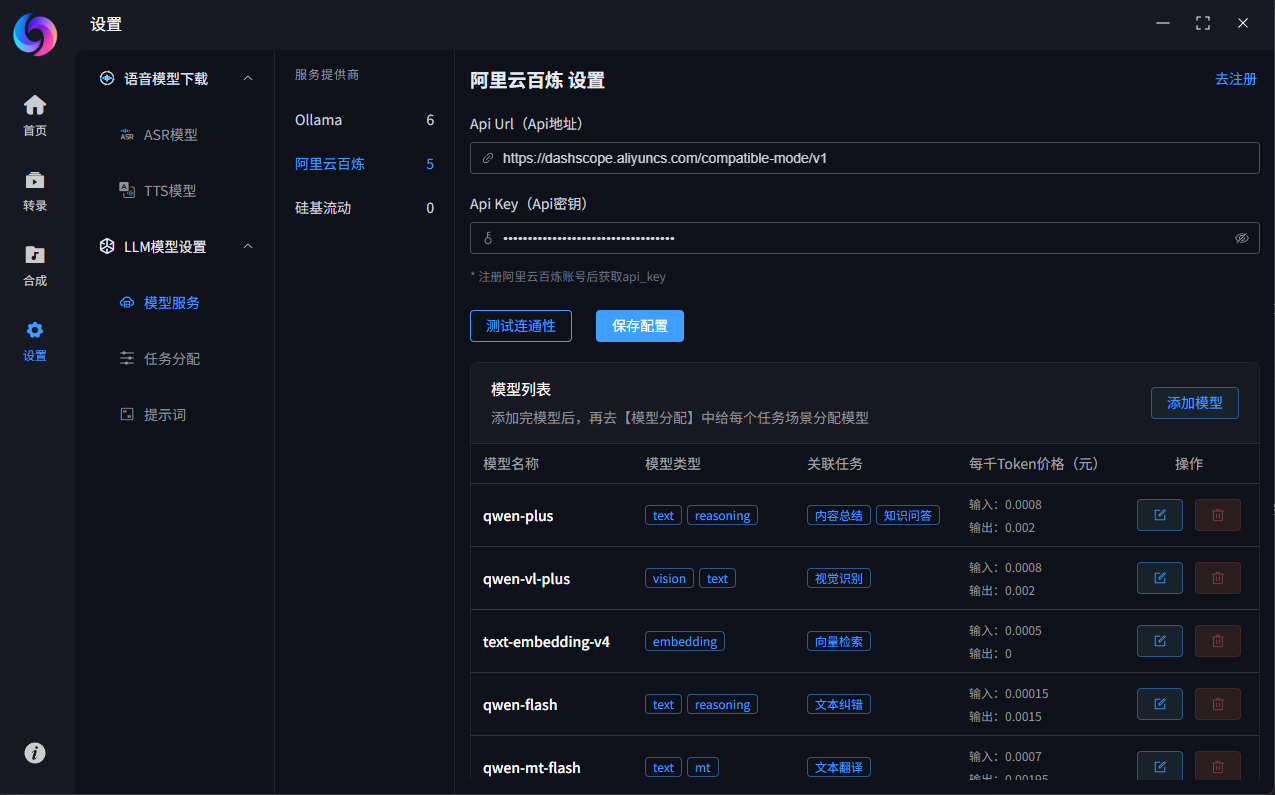
模型任务分配
- 为不同的任务场景分配各自的模型,目前有文本润色、文本翻译、视觉识别、内容总结、向量检索、知识问答这些场景
- 文本润色和文本翻译这种简单的任务建议选择小规格的模型即可,内容总结和知识问答这种复杂任务建议选择高规格模型,以获得更好的效果
- 向量检索任务如果切换了其它Embedding模型,需要重建知识库,否则会导致内容检索失败,所以请谨慎切换。
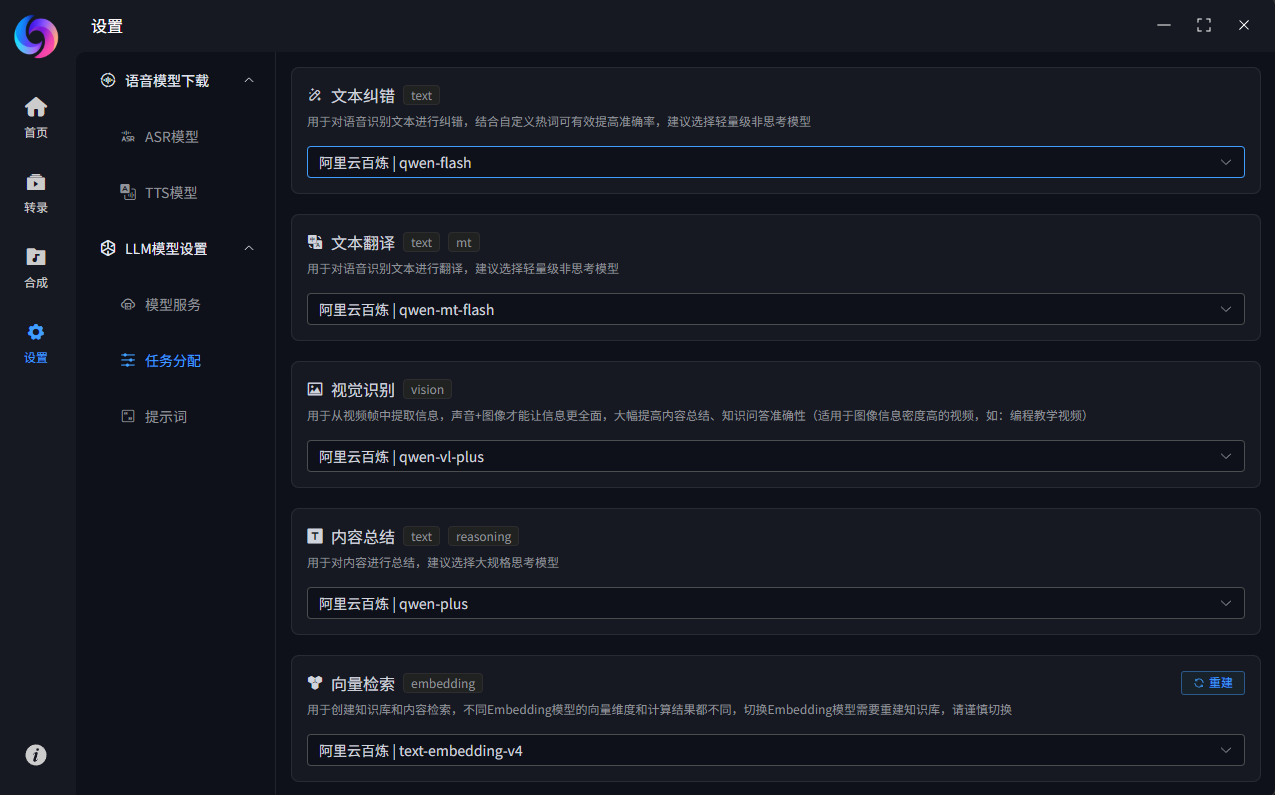
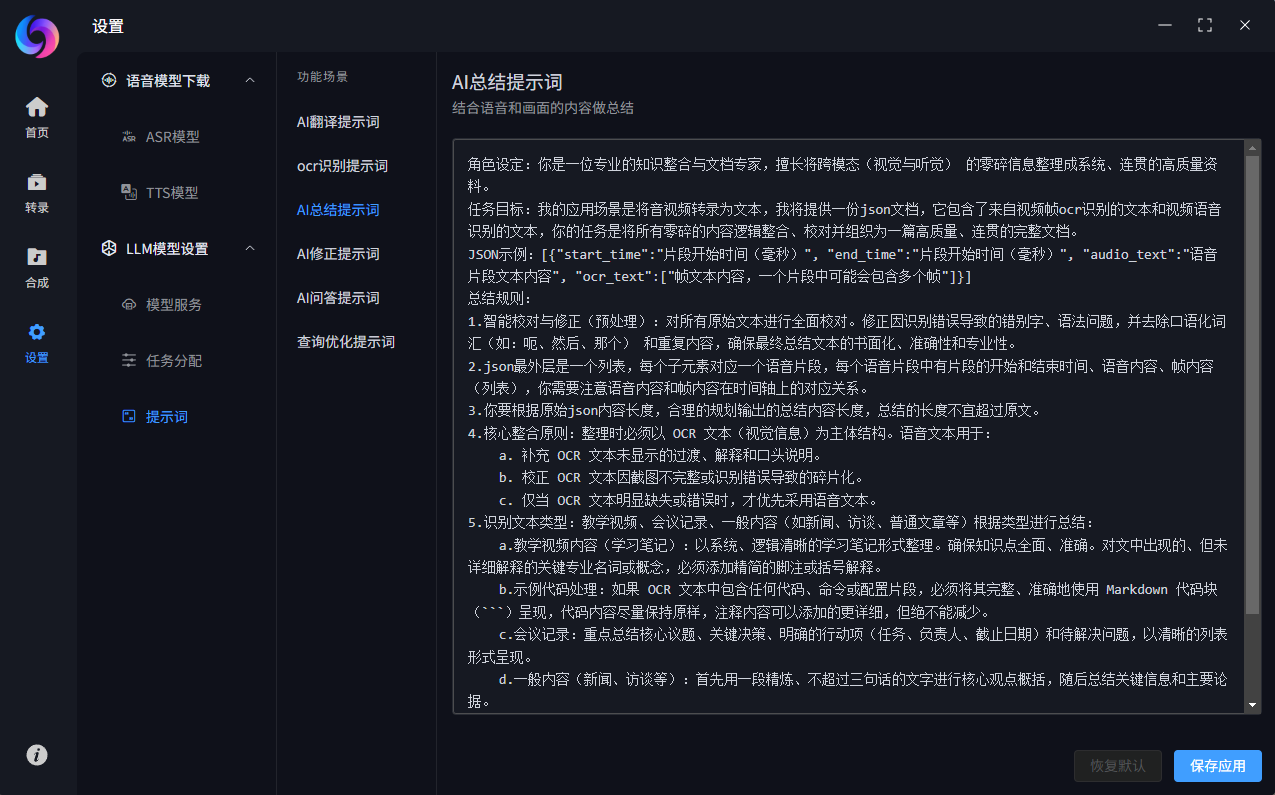
模型提示词设置
每个任务场景预设了一个默认的提示词,如果效果不满意,你可以在设置中修改,修改后如果需要恢复,也可以恢复默认
开始转录
在完成了前面的语音模型下载和模型服务设置步骤后,就可以开始转录了。
- 在线视频转录:直接粘贴 Bilibili、YouTube 或其他主流平台的视频 URL。程序将自动解析和下载资源到本地进行转录
- 本地实时转录:从麦克风或声卡采集实时音频流,边听边转录,注意音量要适中,音量太小或者环境噪音都可能会影响识别效果
- 本地文件转录:从本地选择wav音频或者mp4视频转录
转录中
点击开始转录后,会进入转入中页面,在这里你可以直观的看到转录的进度。以在线转录为例,整个流程为:解析url->下载资源->音频提取->端点检测->语音识别
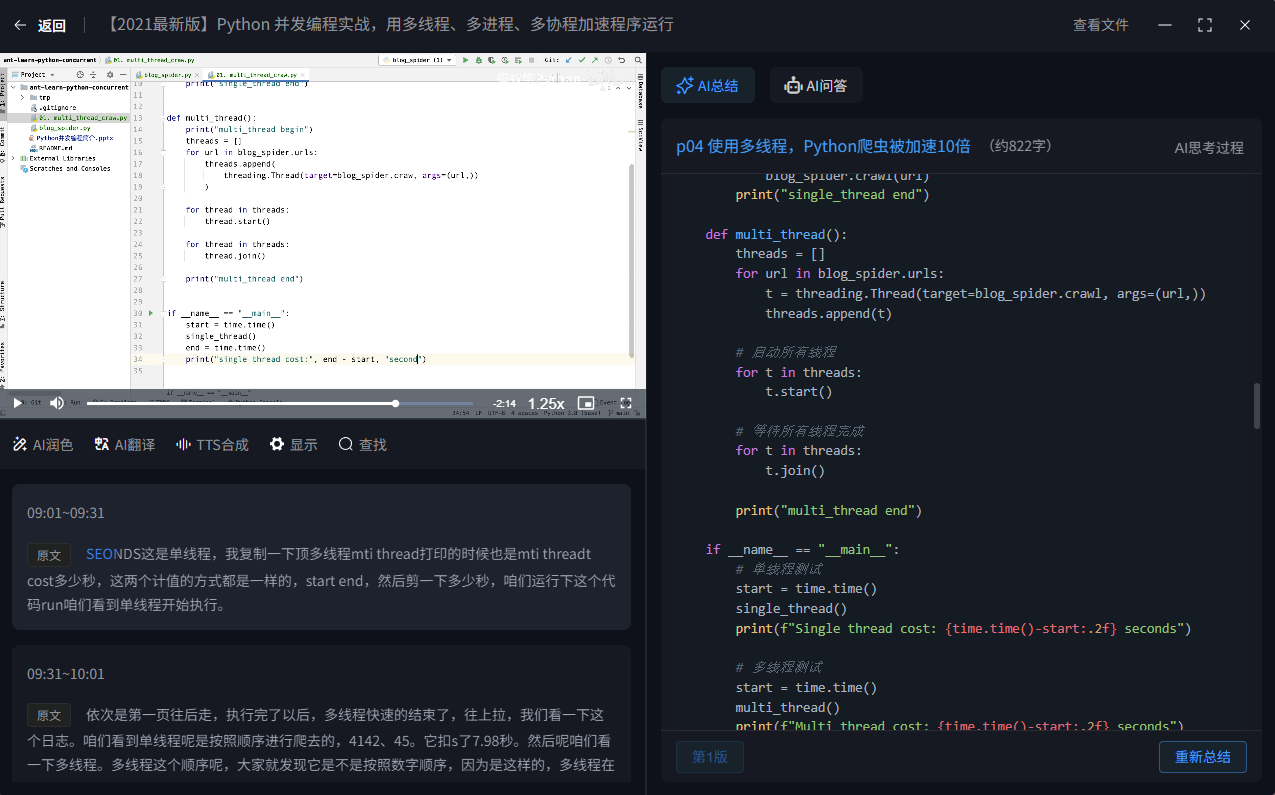
转录完成
转录详情页面,左侧是视频分p栏(仅合集时显示),中间是视频播放器和语音文本时间轴,右侧是AI总结和问答区
在这里你可以使用文本润色、文本翻译、内容总结、知识问答等各种AI功能。
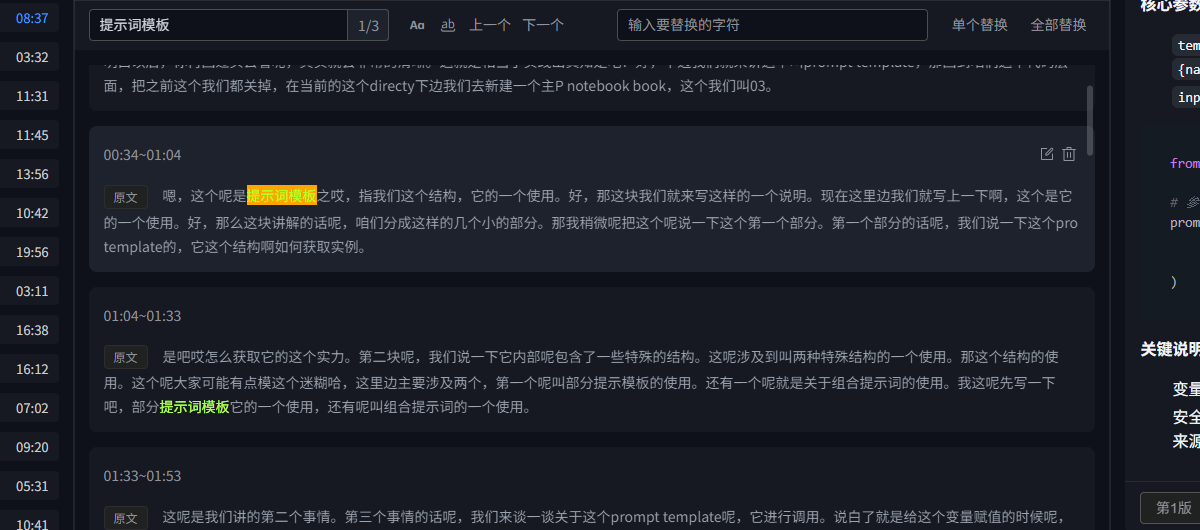
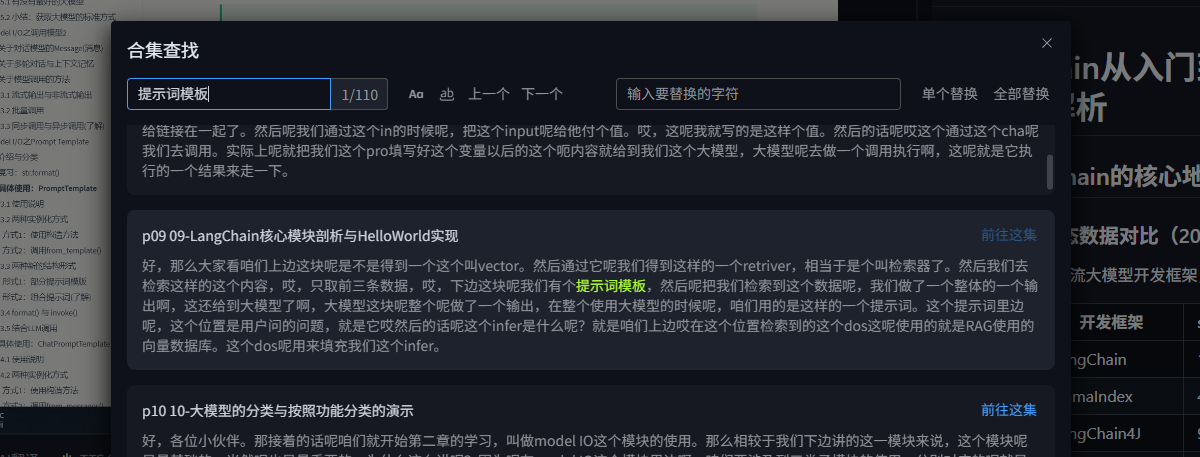
查找替换
语音识别文本难免会出现错别字,为了方便人工校正,可以使用查找替换,来统一修改错别字,针对合集类型的转录可以使用专门的"合集查找",快捷键:单集查找-ctrl+f,合集查找-ctrl+shift+f,关闭-ESC
AI润色
如果原始语音内容比较口语化,你希望得到更书面化的结果,那么可以使用AI润色功能,润色后不仅会更加的书面化,还能够修正一些语音识别的错误,更适合阅读。

AI翻译
翻译效果由模型能力决定
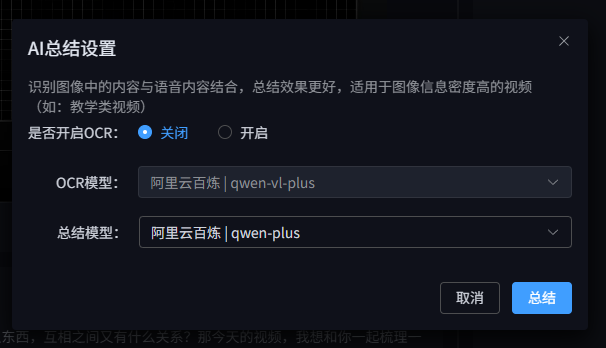
AI总结
总结时可以选择是否开启OCR(视频画面内容识别),对于图像信息密度高的视频墙裂建议开启OCR,总结效果会大大提高
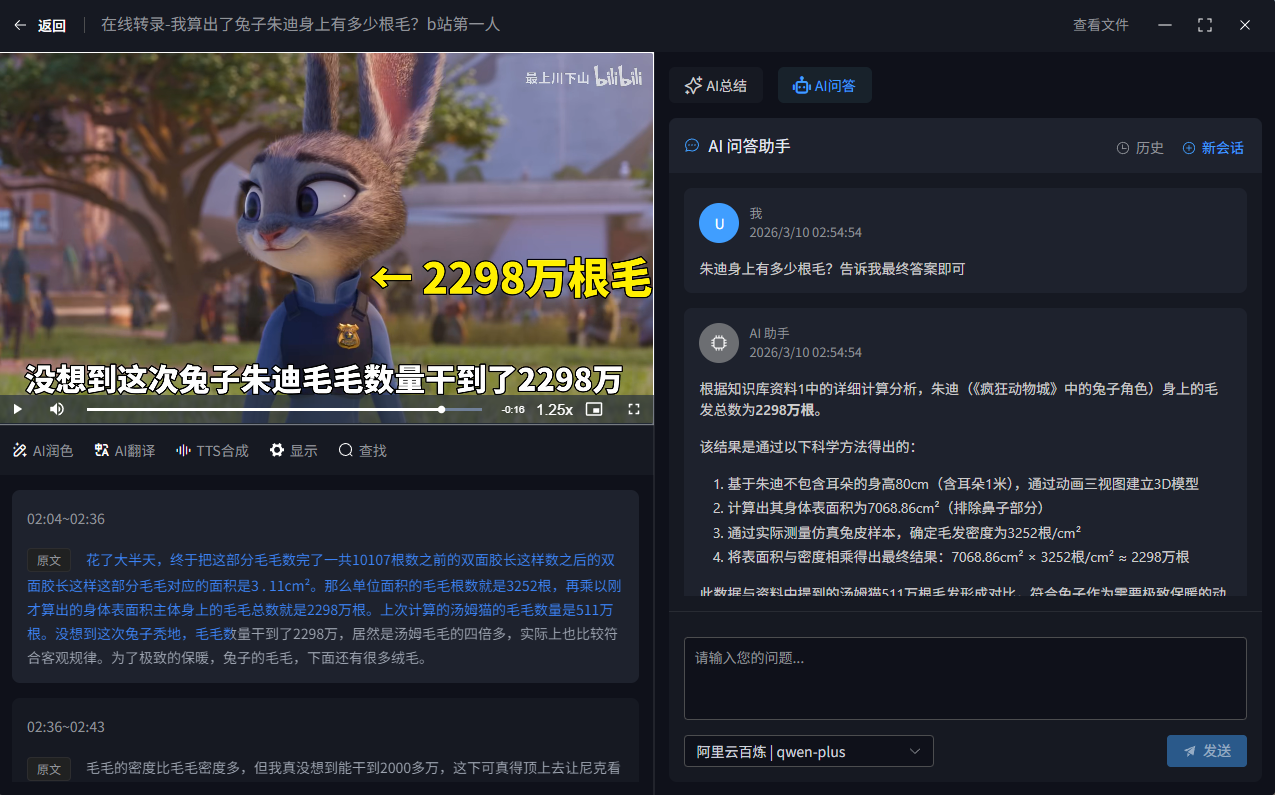
AI问答
那就随便问点奇奇怪怪的问题